Space-Based
- Definition
- A pool of processing units that both contain domain logic and code for a section of the application. New units can be added and removed as load demands.
In a n-tier system, the database is the bottleneck. This pattern tries to solve this by scaling not only code linearly but the data as well.
The pattern gets its name from the concept of tuple space, the technique of using multiple processes communicating through shared memory.
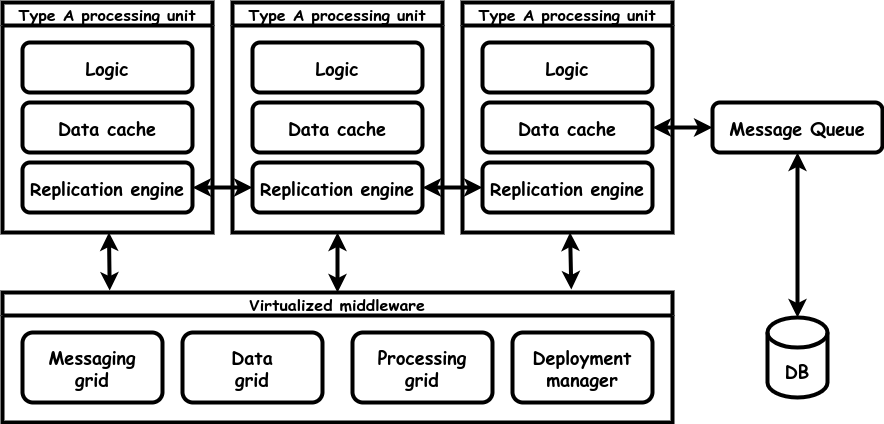
How does it work?
The application is divided in several sections. For example: customer management, product management, order management. Each of the sections has a processing unit type. Each type has a layer of virtualized middleware and a variable number of processing units. Processing units are added and removed based on the load.
The virtualized middleware has
- a messaging grid, which is a load balancer that distributes incoming messages over processing units
- a data grid that holds all data for this section of the application, in memory (not a database), this is the same data as that in the data caches of the processing units
- a processing grid that communicates between processing unit types
- a deployment manager that manages startup and shutdown of processing units based on load
A processing unit contains the logic of a section of the application. It holds a copy of the data grid. It contains a replication engine that duplicates its data to the other processing units of the same type. This data replication is very fast, but not immediate. It's based on a replication frequency. Multiple variants of replication are available, where the data grid may or may not be involved.
Every mutation is not only replicated to the other processing units, but send as a message to the database. The database is also used to feed the first processing unit of an area.
Examples
- Large cloud providers like Google and Amazon
- JavaSpaces
When should you use it?
- This is a complex architecture that should be used only when the database is a serious bottleneck. Further, it works better with compartimentable data sets and heavy processing.
Problems
- As different processing units work on copies of the data, data collisions may occur when multiple units change the same tuple at about the same time. When replication frequency is low, the chance of data collision (and corruption) is higher.